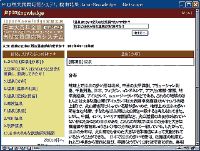
このシステムは出来上がった文章の中から誤字脱字誤変換を指摘し可能な場合には正解候補を表示します。
これまであった他社システムのような校正ルールは必要ありません。大量の文章データから校正ルールを自動的に学習しますので、システムを即使えるようになりますし、特殊な分野の文章に対しても容易に対応することが可能になりました。 このシステムにより、これまでエキスパートに頼っていた校正作業の 効率化を図ることができます。
言葉を調べるためには、言葉が実際にどのように使われているかを調べる必要があります。例えば、WEBには膨大な数の文章があります。この言葉の宝庫を対象に、言葉がどのように使われているのかを調べる1つの方法がKWIC(KeyWord In Context)です。
調べたい言葉や文字列を入力すると、その言葉が使われている文を大量に得ることが出来ます。研究教育目的に限り、WEB文書を対象にしたシステムをご提供いたします。
ASIMOやQRIOなど2足歩行ロボットが実現され、現実は鉄腕アトムの夢へ近づいてきています。 しかし、肉体はできてきていますが、頭脳はどうなっているのでしょうか?
私たちは、現在研究されている自然言語処理という技術を結集して、小学2年生の国語の問題を解くプログラムを製作しています。現在の能力は大体70点くらいです。
まだまだ、これからいろいろなことを学習していい成績を目指して頑張っていきます。
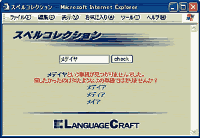
検索システムに、「メデイヤ」や「肝が座る」と入力しても何も見つからないといった経験はありませんか?
これは、そのシステムでは「メディア」や「肝が据わる」と綴っていたために起ったのです。
このように、キーワード検索などの際に、片仮名表現の揺れや漢字変換ミス等で求めている情報が得られないことがよくあります。 このような表現の揺れや間違いに対処し、辞書から適切な単語を探し出すシステムが、スペルコレクションです。
例えば、「日本に温泉は何か所あるのか」知りたい時、どうやって探しますか?
キーワード検索を駆使してもなかなか見つかりません。「温泉」の項目を上から下まで読みますか?
質問応答システムでは、「日本に温泉は何か所ありますか」という普通の質問文で聞くと、答えも「2431」とズバリ返します。 現在の技術では100%の精度というわけには行きませんが、これまでの検索技術と組み合わせることによって利便性の向上が図れます。
WEBの検索エンジンは、WEBページを検索します。でも、あなたが欲しいのは「ある映画の監督の名前」や「日本で取れるワインの銘柄のリスト」や「火星の写真」ですよね?
例えば「ETを取った監督は誰?」と聞くと「スティーブン・スピルバーグ」と答え、「火星の写真が欲しい」と聞くと、その写真が表示されるというものです。
様々な「知りたいもの」に対して、普通の会話のように問いかけると、本当に知りたい事柄や リストなどが、知りたい形で出てくるシステムを開発しています。
提供先:
ネットアドバンス社
様
「省エネ」で新聞記事を検索したら、結果の上位には、自動車、電気製品での省エネ、サマータイムの導入のような記事ばかり。本当は世界各国の取り組みを知りたかったのに というようなことはありませんか?
検索結果を見やすくするために「サマータイム」「電気製品」「各国の取り組み」といった同じテーマの情報をまとめてくれれば、すぐに欲しい情報に辿り着いたはずです。このように、見つかった情報を内容によって分類し表示する技術がテキストクラスタリングです。
人間の持つ言葉の単位は単語であり、文でありドキュメントです。このような知識を収集、分析、組織化し、応用していくことが言葉を研究する我々の使命です。
本研究所ではこれまでも、百科事典の見出し項目の分類、新聞記事にある固有名詞などのアノテーション、新聞記事の要約や重要項目分析データ作成、機械マニュアルの言語的解析など、辞書、データ作りを通して言葉の研究に携わって参りました。
本研究所は自然言語処理の分野で活躍しているニューヨーク大学の関根助教授を中心とした研究所です。
コンピュータが我々の生活に身近になり、「言葉」に関する研究成果が広く世の中の役に立つ時代になりました。
この自然言語処理の最先端の技術を、研究の世界から応用の世界へ橋渡しをしたいと考えています。
ここに上げた技術以外にも、情報抽出、テキストマイニング、情報検索、言語解析、機械学習などの技術を研究してまいりました。
提供先: (株)山武 ビルシステムカンパニー 様
提供先:独立行政法人通信総合研究所 様
ホーム
製品紹介
会社概要
お問い合わせ
日本語Proofreader
KWIC on WEB
電脳優子2年生
スペルコレクション
質問応答システム
統合情報アクセスシステム
テキストクラスタリング
辞書データ作成